Uso do Databricks para Processamento de Streaming em Tempo Real
Processamento de streaming
O processamento de streaming é uma abordagem computacional que lida com a análise e processamento de dados que são gerados em tempo real, à medida que são recebidos. Em contraste com o processamento de lote, em que os dados são coletados e processados em blocos, o processamento de streaming permite lidar com a natureza contínua e em tempo real dos dados.
No processamento de streaming, os dados são recebidos como fluxos contínuos que podem ser originados de várias fontes, como sensores, dispositivos IoT, mídias sociais, transações financeiras, registros de servidores, entre outros. Esses fluxos de dados são processados em pequenas parcelas ou eventos individuais, à medida que são recebidos, em vez de esperar por uma coleção completa de dados.
Essa forma de processamento em tempo real permite que organizações monitorem, analisem e tomem decisões com base em informações atualizadas e em constante evolução. Com o processamento de streaming, é possível identificar eventos ou padrões instantaneamente, detectar anomalias, realizar análises complexas e acionar respostas automáticas em tempo real.
O processamento de streaming é amplamente utilizado em várias indústrias, como finanças, mídia, saúde, logística e manufatura. Ele tem aplicações em detecção de fraudes, monitoramento de segurança, análise de sentimentos em tempo real, personalização de conteúdo, previsão de demanda, entre muitos outros casos de uso.
Processamento de Streaming utilizando Databricks
O Databricks destaca-se como uma plataforma robusta para o processamento de dados em tempo real, capacitando as organizações a extrair insights valiosos e tomar decisões ágeis ao aproveitar o potencial dos dados em movimento. Com o Databricks, é viável
absorver grandes volumes de dados de diversas fontes em tempo real e processá-los prontamente para análises imediatas.

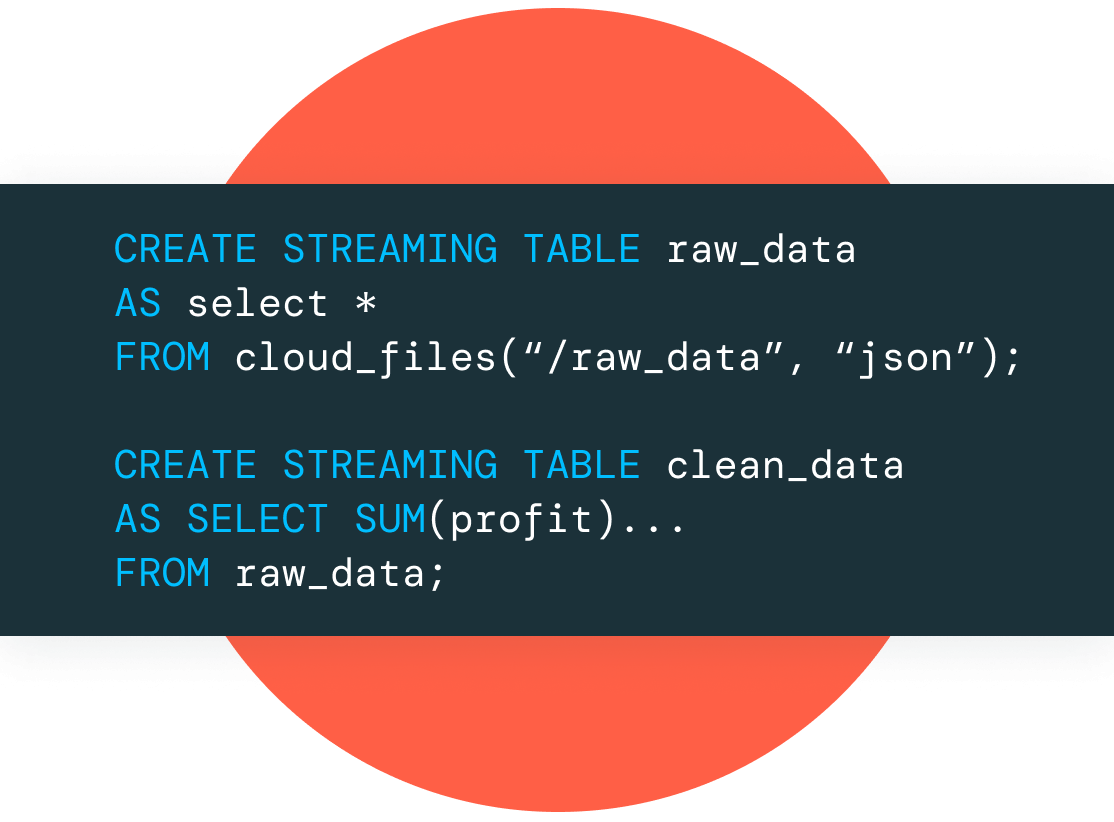
Deste modo, um dos pilares fundamentais para o processamento de streaming no Databricks é o Apache Spark Streaming. Essa ferramenta permite que os dados de streaming sejam segmentados em micro lotes e processados em intervalos regulares. Essa abordagem capacita as organizações a analisar e agir sobre os dados enquanto eles estão sendo gerados.
O
Spark Streaming
no Databricks disponibiliza uma API de alto nível e de fácil utilização, permitindo a manipulação e transformação eficientes dos dados de streaming. Ele suporta uma vasta gama de fontes de dados de streaming, incluindo Kafka, Flume, HDFS, entre outros. Além disso, o Databricks oferece recursos avançados, como integração com o Delta Lake, fornecendo um sistema robusto e confiável para armazenamento e processamento de dados de streaming.

Uma das vantagens primordiais é sua capacidade de escalar de forma horizontal a infraestrutura de processamento conforme a demanda. Com a habilidade de provisionar automaticamente clusters de máquinas, o Databricks assegura que os dados de streaming sejam processados de forma rápida e eficiente, mesmo em situações de alta demanda.
Ele oferece às organizações a capacidade de tomar decisões embasadas em dados atualizados, possibilitando a detecção precoce de padrões e tendências, monitoramento em tempo real de eventos críticos e ações imediatas com base nos dados de streaming. Trata-se de uma ferramenta indispensável para empresas que almejam manter-se à frente da concorrência e capitalizar o valor dos dados em movimento.
Ao fornecer uma arquitetura altamente escalável e flexível para o processamento de dados de streaming em tempo real, utiliza o conceito de "dados em movimento" para ajudar as organizações a lidarem com a natureza dinâmica dos dados gerados em tempo real.
Assim, suporta diversas abordagens, como processamento de eventos individuais, processamento em janela e processamento contínuo, permitindo às organizações escolher a estratégia de processamento mais adequada para suas necessidades específicas.
No processamento de eventos individuais, cada evento é processado assim que é recebido, possibilitando uma análise e tomada de decisão extremamente ágil. Essa abordagem é ideal para casos de uso em que a latência é crucial e ações imediatas precisam ser tomadas com base nos eventos em tempo real.
Já o processamento em janela é útil quando se deseja analisar dados em um intervalo de tempo específico, como uma janela deslizante de 10 minutos. Essa abordagem permite às organizações identificar padrões ou anomalias em um conjunto de dados limitado, sendo particularmente útil para aplicações de monitoramento em tempo real.
Por fim, o processamento contínuo envolve a análise e agregação constantes de dados em movimento. Nessa abordagem, as organizações podem acompanhar métricas em tempo real, calcular médias, somas, contar eventos e atualizar continuamente os resultados à medida que novos dados chegam. Isso é útil em casos de uso como análise de fluxo de cliques, monitoramento de redes ou análise de dados de produção em tempo real.
Além das abordagens de processamento, o Databricks oferece recursos poderosos para o gerenciamento de dados de streaming, como ingestão de dados de diversas fontes, integração com sistemas de mensagens como o Apache Kafka e suporte a formatos de dados comuns, como Avro, JSON e Parquet. Isso garante que as organizações possam receber, processar e armazenar dados de streaming de forma eficiente e segura.
O Databricks também suporta o uso de algoritmos de machine learning em tempo real, permitindo que as organizações apliquem modelos de aprendizado de máquina aos dados de streaming para detecção de fraudes, recomendações em tempo real, personalização de conteúdo, entre outros.
Deste modo, as organizações podem extrair o máximo valor dos dados em movimento, identificando oportunidades, detectando eventos críticos e tomando decisões rápidas e informadas com base em informações atualizadas. Trata-se de uma ferramenta essencial para empresas que buscam manter-se à frente da concorrência e prosperar em um mundo de dados em tempo real.
Em resumo, o Databricks possui uma série de recursos que o tornam uma excelente escolha para o processamento de streaming em tempo real. Alguns dos principais recursos incluem:
Escalabilidade: O Databricks é altamente escalável, permitindo o processamento de grandes volumes de dados em tempo real. Ele pode lidar com fluxos de dados de alta velocidade e dimensionar de forma automática recursos conforme necessário.
Integração com ecossistema Apache Spark: O Databricks é construído em cima do Apache Spark, uma das principais estruturas para processamento de big data. Ele oferece integração nativa com o Spark Streaming, permitindo aproveitar todos os recursos e funcionalidades do Spark para o processamento de streaming.
Ferramentas visuais e colaboração:
O Databricks oferece uma interface de usuário intuitiva e simplificada, facilitando o desenvolvimento e a implantação de pipelines de streaming em tempo real. Ele também suporta a colaboração em tempo real, permitindo que equipes colaborem e compartilhem conhecimento de forma eficiente.
Suporte a várias fontes de dados: O Databricks oferece suporte a uma ampla variedade de fontes de dados, incluindo bancos de dados, data lakes, sistemas de mensagens como o Apache Kafka e muito mais. Isso permite a ingestão fácil e contínua de dados em tempo real de várias fontes.
Recursos avançados de processamento: O Databricks oferece recursos avançados de processamento de streaming em tempo real, como processamento de eventos individuais, processamento em janelas de tempo e processamento contínuo. Ele também suporta streaming de alto throughput e latência ultrabaixa para casos de uso exigentes.
Integração com machine learning
O Databricks permite aplicar algoritmos de machine learning em tempo real aos dados de streaming. Isso permite a detecção de padrões, a geração de insights acionáveis e a automação de decisões em tempo real.
Esses são apenas alguns dos principais recursos do Databricks que o tornam uma escolha certa para o processamento de streaming em tempo real. Sua combinação de escalabilidade, integração com Spark, ferramentas visuais, suporte a várias fontes de dados, recursos avançados de processamento e integração com machine learning o tornam uma opção atraente para organizações que lidam com dados em constante evolução.
Fontes:
Streaming de dados - Análise em tempo real, ML e aplicativos simplificados
https://www.databricks.com/product/data-streaming
Transmissão no Databricks
https://docs.databricks.com/pt/structured-streaming/index.html
Consultar dados de transmissão
https://docs.databricks.com/pt/query/streaming.html
Compartilhe

