Construindo Data Warehouse no Databricks: Uma Abordagem para seu Lakehouse
Fonte: Databricks
Data warehousing, no contexto da Databricks, representa a coleta e armazenamento de dados provenientes de diversas fontes, visando a rápida acessibilidade para análises comerciais e geração de relatórios. Este artigo visa explorar conceitos fundamentais para a construção eficiente de um data warehouse em seu ambiente de data lakehouse.
Data Warehousing em seu Lakehouse
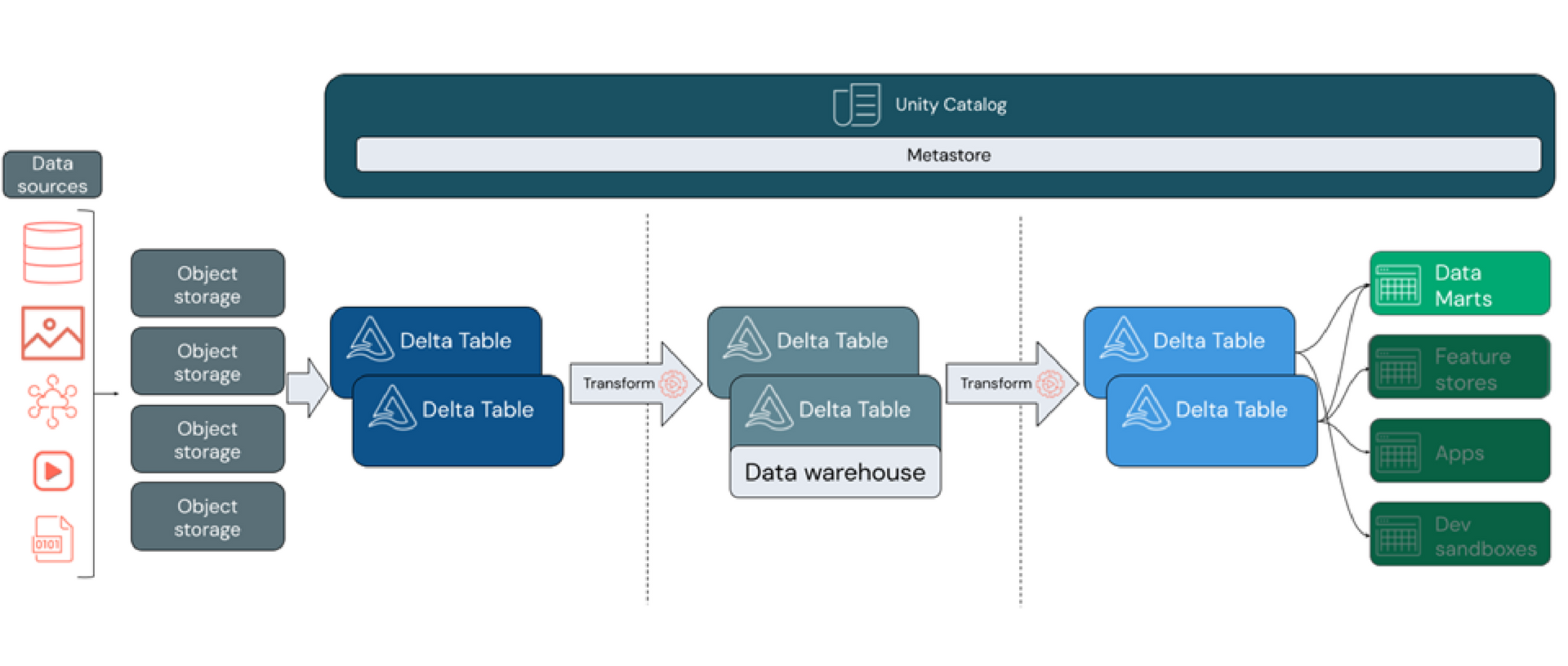
A arquitetura lakehouse e a utilização do Databricks SQL trazem recursos avançados de data warehousing para o seu data lake. Através do uso de estruturas de dados familiares, relações e ferramentas de gerenciamento, é possível modelar um data warehouse de alto desempenho e eficiente, executado diretamente em seu data lake.
Ao contrário dos data warehouses tradicionais, a construção de um data warehouse dentro do seu lakehouse oferece a vantagem de reunir todos os dados em um único sistema. Isso elimina a necessidade de isolar dados analíticos de negócios ou criar cópias redundantes que rapidamente se tornam obsoletas.
Ao incorporar recursos como o Unity Catalog e o Delta Lake, o DataBricks proporciona um modelo de governança unificado. O Unity Catalog permite a proteção e auditoria do acesso aos dados, enquanto o Delta Lake adiciona transações ACID e evolução de esquema, garantindo dados confiáveis, escaláveis e de alta qualidade.
O Papel do Databricks SQL
O Databricks SQL, parte integrante dos serviços oferecidos, traz consigo recursos e desempenho de data warehousing para seu data lake existente. Com suporte a formatos abertos e SQL ANSI padrão, o Databricks SQL fornece um editor SQL na plataforma, permitindo a colaboração direta entre membros da equipe no workspace.
Este serviço não apenas suporta o SQL warehouse, mas também oferece recursos de computação escalável desacoplados do armazenamento. A integração com o Unity Catalog possibilita a descoberta, auditoria e controle eficientes de dados ativos em um único local.
Modelagem de Dados no Databricks
A abordagem de lakehouse suporta diversos estilos de modelagem, sendo a arquitetura medallion uma opção popular. Esta arquitetura implementa camadas de dados cada vez mais refinados à medida que "evoluem" nas camadas, proporcionando uma estrutura básica no lakehouse. As camadas bronze, prata e ouro indicam a progressão da qualidade dos dados, sendo o ouro representando a mais alta qualidade.
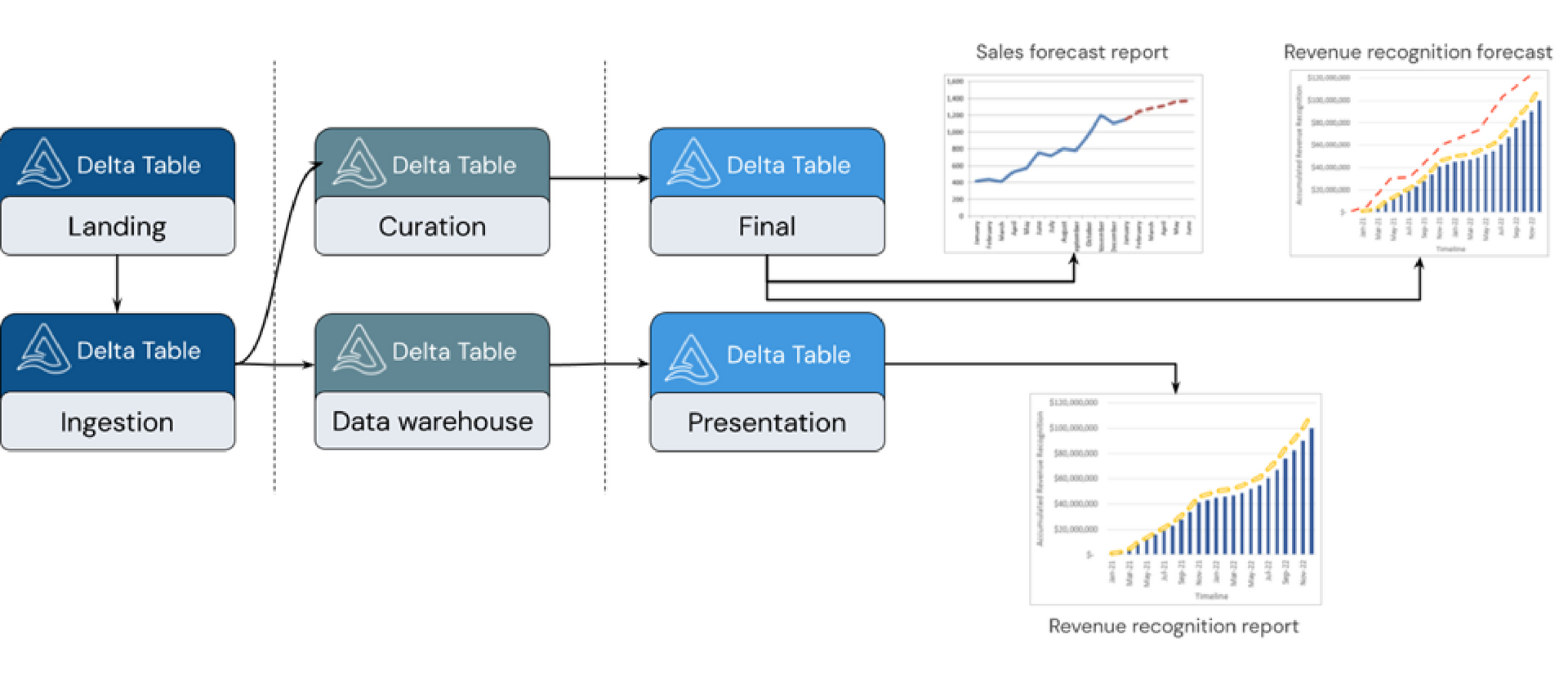
Na camada bronze, os dados brutos entram no lakehouse em seu formato original, sendo convertidos em tabelas Delta. A camada prata reúne dados de diferentes fontes, permitindo a curadoria de dados ativos significativos, muitas vezes focado em velocidade e agilidade.
A camada prateada também é o local para integrar dados de fontes diversas, construindo um data warehouse alinhado aos processos de negócios existentes. O data warehouse é um esquema na gravação e atômico, otimizado para mudanças rápidas quando os processos de negócios evoluem.
A camada ouro, por sua vez, é a camada de apresentação, abrigando data marts e modelos dimensionais. Essa camada suporta sandbox departamental e de ciência de dados, permitindo o auto serviço analítico e de ciência de dados em toda a empresa, sem a necessidade de cópias de dados fora do lakehouse.
Conclusão
Em síntese, a construção de um data lakehouse no Databricks oferece uma abordagem moderna e eficiente para lidar com grandes volumes de dados. A integração do Databricks SQL e a modelagem de dados em camadas proporcionam flexibilidade, escalabilidade e confiabilidade, essenciais para atender às demandas analíticas e de relatórios em ambientes empresariais dinâmicos.
A Five Acts é parceira da Databricks. Fale com um de nossos consultores e saiba mais sobre como podemos te ajudar a ter uma plataforma de dados unificada e gerar valor para o seu negócio de forma mais rápida.
Compartilhe

